Creating a Gradio App for Audio-to-Meeting-Minutes with Whisper and Llama
In this post, I'll walk through how I am able to build a meeting minute generator in a simple Gradio app.
The goal of this project is to upload a file in Gradio interface, and instantly get back structured meeting minutes and key points!
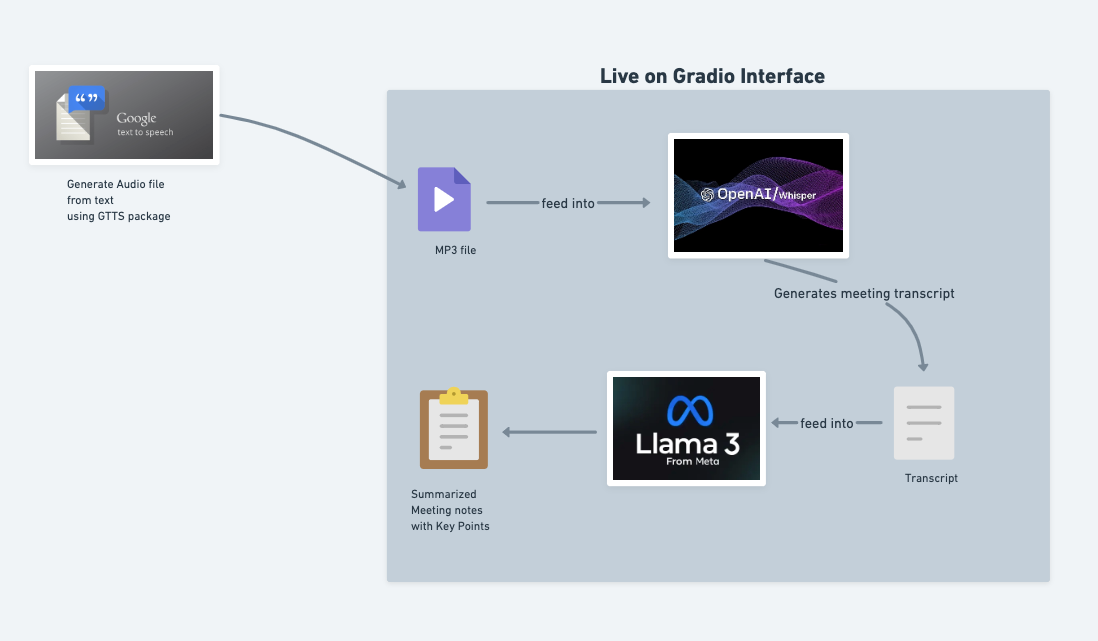
Below is a simple workflow diagram on how it works.
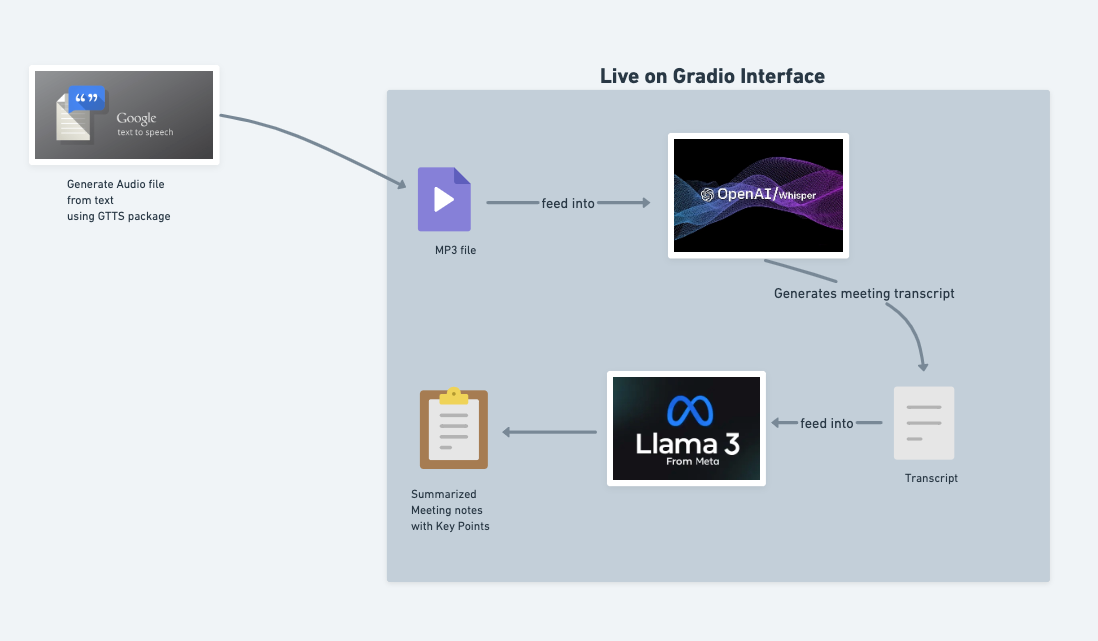
Step 1: Generate Audio from Text with GTTS
Everything starts with the Google Text-to-Speech (GTTS) package. I use GTTS to convert any meeting script or text into an MP3 audio file. This is especially handy for testing or when you want to simulate meeting recordings without needing a live speaker.
Step 2: Transcribe Audio with OpenAI Whisper
Once I have the MP3 file, it’s fed directly into OpenAI Whisper. Whisper is a state-of-the-art speech-to-text model that quickly turns the audio into a detailed transcript. This step is fully automated within the Gradio interface-just specify the file path, and Whisper does the rest.
Step 3: Extract Meeting Minutes with Llama 3
The transcript generated by Whisper is then passed to Llama 3 from Meta. Here, I use a carefully crafted prompt to instruct Llama 3 to extract structured meeting minutes, including:
- A summary with attendees, location, and date
- Key discussion points
- Takeaways
- Action items with owners
Llama 3 outputs the results in markdown format, making them easy to read, share, or integrate into documentation.
Step 4: All in a Gradio Interface
The entire workflow runs seamlessly through a Gradio interface. You simply provide the audio file path, and the app returns summarized meeting notes with key points-no manual steps required.
GTTS: Generate audio file from text.
Whisper: Transcribe audio to text.
Llama 3: Summarize transcript into meeting minutes.
Gradio: One interface to run the whole pipeline.
Below are a few screenshots of how it actually looks like!
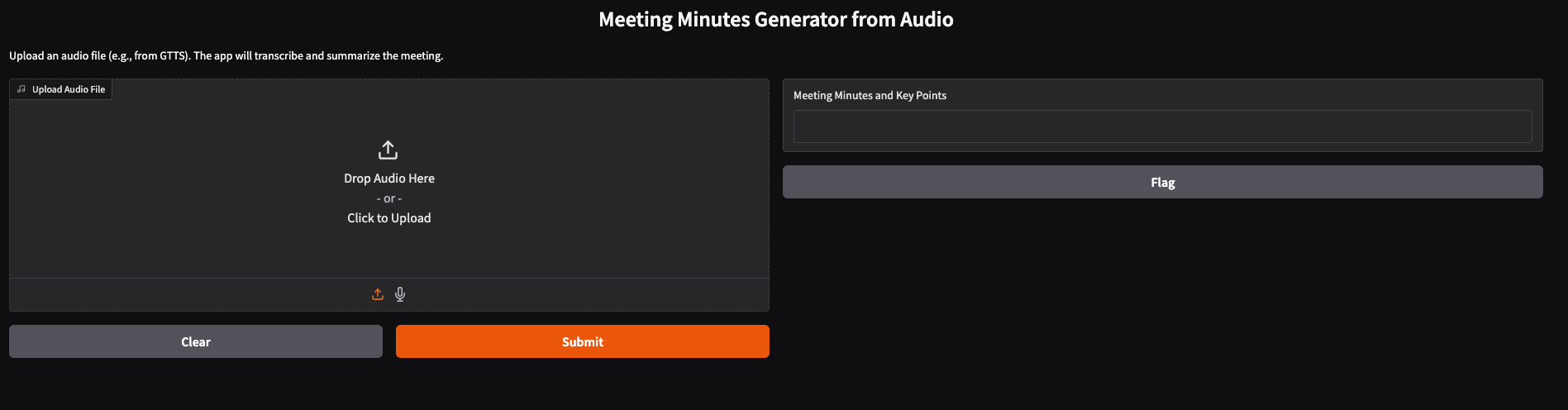
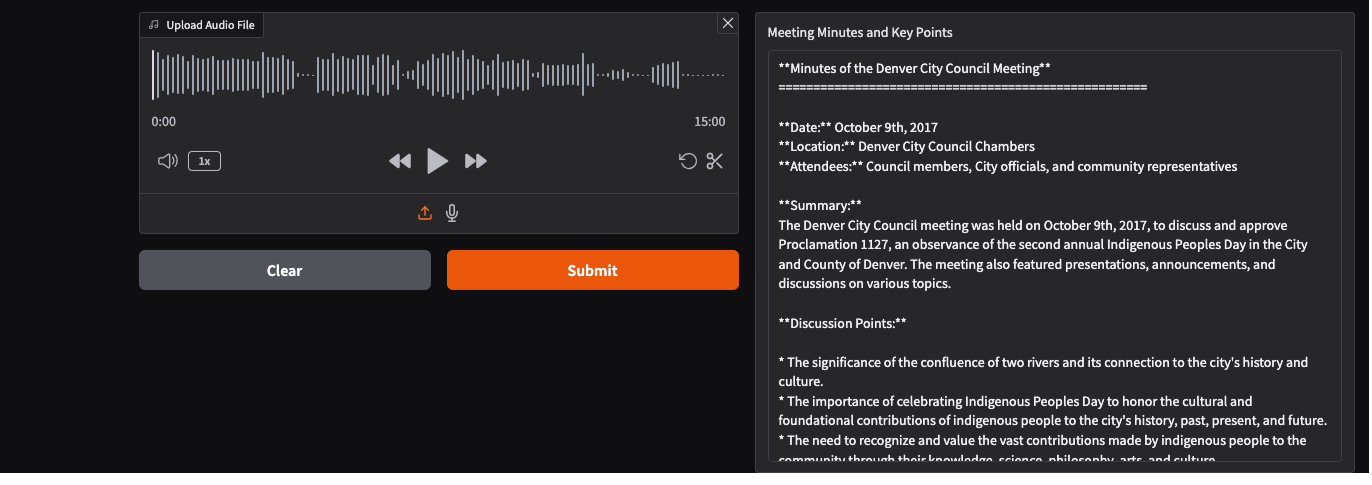
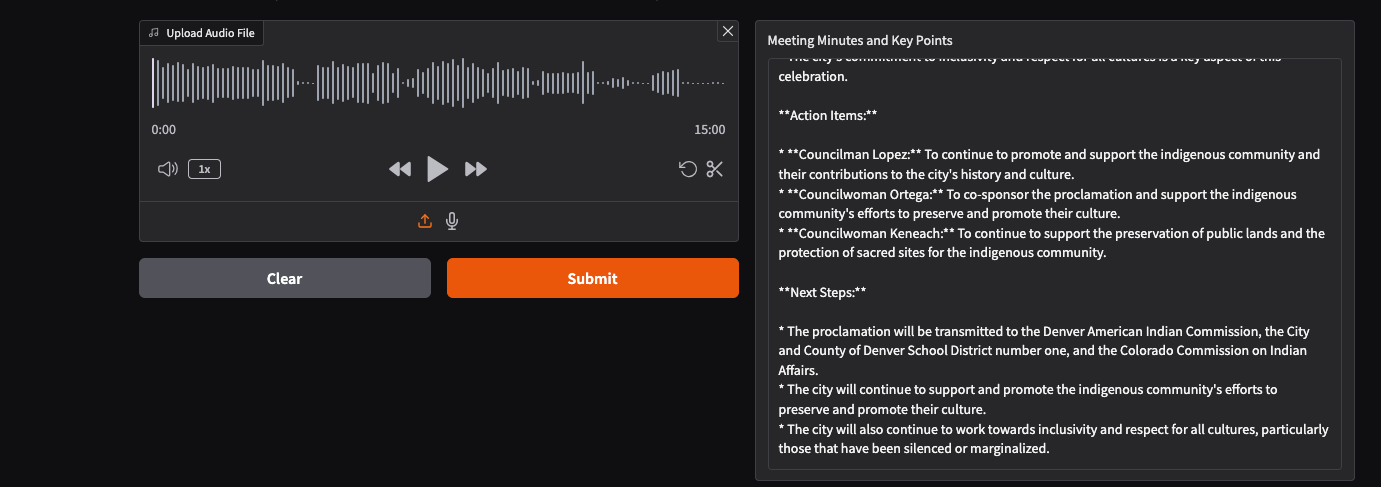
This setup is ideal for automating meeting documentation, whether you’re working with real recordings or synthetic audio. It’s fast, reliable, and easy to use-just point to your audio file and let the models handle the rest.