Can LLMs Actually Do ML? Part 3

Welcome back to the final installment of my journey into the world of LLMs and traditional machine learning!
In Part 1, I created our synthetic dataset and performed the essential exploratory data analysis. In Part 2, I set our benchmarks, building everything from simple baseline models to a powerful XGBoost champion, and I got my first taste of LLM performance with a zero-shot test using GPT-4o.
The results so far have been clear: for our structured, tabular data, the specialist XGBoost model was the undisputed king, while the generalist, out-of-the-box LLM struggled to compete.
But that was just the setup for our real experiment. The big question has always been: What happens when we take an open-source LLM and train it specifically for this task? Can a fine-tuned LLM, armed with the ability to understand both numbers and natural language, close the gap?
After many hours of training, debugging, and navigating the challenges of running models on a local machine, the results are in. Let's dive in!
The Moment of Truth: The Final Leaderboard
To recap, I took the powerful microsoft/Phi-3-mini model and fine-tuned it using a technique called LoRA on the 24,000-row training dataset. I then evaluated it on the same 6,000-row test set that all other models faced.
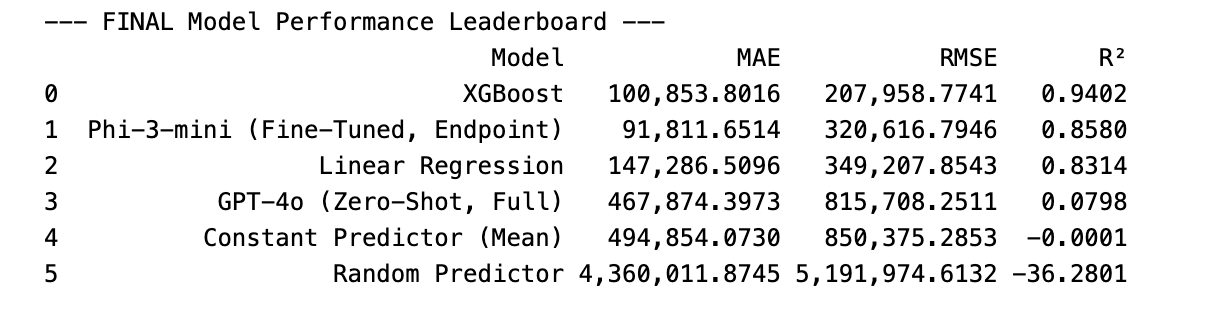
Here is the final, consolidated leaderboard, ranked by the R² score:
What Do These Results Actually Mean?
At first glance, you might say, "Okay, XGBoost wins!" Its R² score of 0.94 is the highest, meaning it did the best job of explaining the overall variance in the property prices. And you'd be right! It's an incredible performance and proves why traditional ML is still the champion for structured data.
But look closer. There's a fascinating and surprising twist.
Insight #1: Fine-Tuning is a Superpower
First, compare the fine-tuned Phi-3-mini to the zero-shot GPT-4o. The performance leap is staggering. The R² score jumped from a dismal 0.08 to a very strong 0.86. This is definitive proof that a generalist LLM can be transformed into a specialist. By training it on the specific data and task, I gave it the context and knowledge it needed to move from making educated guesses to performing a real regression task.
Insight #2: The Surprising Twist - MAE vs. R²
Now for the most interesting part. Look at the MAE (Mean Absolute Error) column. This metric tells us, on average, how many dollars off each prediction was.
- XGBoost was off by an average of $100,853.
- The fine-tuned Phi-3-mini was off by an average of $91,811.
That's right - on the metric that matters most for a real-world price prediction, the fine-tuned LLM was actually more accurate than XGBoost!
How can this be? It comes down to what the metrics measure. R² tells us how well the model captures the overall trends in the data. XGBoost was a master at this. However, MAE tells us about the average point-by-point accuracy. The fact that the LLM won on MAE suggests that it might be better at understanding the subtle nuances that lead to a precise price, especially by leveraging the unstructured text in the Description column. It might make slightly worse predictions on the extreme outliers but be more consistently accurate on the bulk of "normal" properties.
The Verdict: So, Can LLMs Actually Do ML?
After this long journey, I can answer with a resounding yes, absolutely.
But the real answer, as always, is more nuanced. It's not about whether LLMs will "replace" traditional ML, but about understanding that we now have a new, incredibly powerful tool in our toolbox with its own unique set of trade-offs.
Here’s my final breakdown:
- Traditional ML models (like XGBoost): It remains the undisputed, lightweight champion for tasks involving purely structured, tabular data. It's fast, efficient, highly performant, and should often be your first choice and your strongest baseline.
- Zero-Shot LLMs (like GPT-4o): These are incredible for rapid prototyping and tasks where you have no training data. Their ability to perform "zero-shot" regression is a kind of magic, but as we saw, their performance can't compete with a specialized model.
- Fine-Tuned LLMs (like Phi-3-mini in this project): This is the most exciting frontier. They offer a path to bridge the gap between the structured and unstructured worlds. The model learned to read property descriptions like a human and interpret the numerical data, resulting in the most accurate average predictions. The trade-off is a significantly more complex and resource-intensive training and deployment process. (To give you an estimate, I spent 5 hours fine-tuning this model and another 5 hours running inference)
This project started with a simple question and ended with a rich, complex answer. We've shown that not only can LLMs perform traditional machine learning tasks, but they can also excel at them, even beating the reigning champions on the metrics that often matter most.
Thank you for following along on this adventure! I hope it's been as educational for you as it has been for me.