Can LLMs Actually Do ML? Part 2

This is the follow-up to my weekend experiment testing whether LLMs can handle traditional ML tasks. Part 1 is here if you missed it.
Quick recap: I created a synthetic property dataset using three different LLMs, ran some baseline models, and found that XGBoost came out on top among traditional models. Now it's time to see how LLMs stack up.
Preparing the dataset for LLMs
Before throwing my dataset at various models, I needed to convert the tabular data into something LLMs can actually work with – natural language prompts.
As a reminder, here's what my raw dataset looks like:
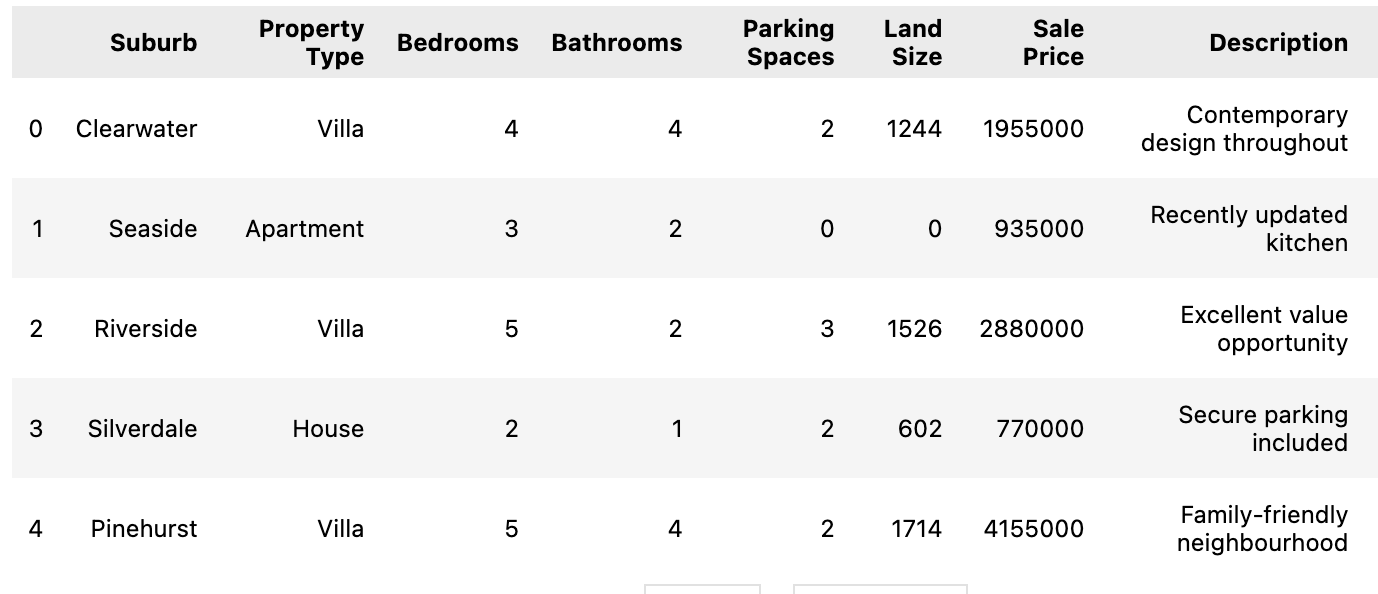
I need to add a column so that it takes the data from all columns (including Description) and generates a complete description of the house.
I wrote a simple Python function to turn each row into a conversational prompt:
def create_llm_prompt(row):
"""
Takes a row of the dataframe and creates a detailed natural language prompt.
"""
# Using an f-string for easy formatting.
# We'll handle cases where bedrooms/bathrooms are singular.
bed_str = "bedrooms" if row['Bedrooms'] > 1 else "bedroom"
bath_str = "bathrooms" if row['Bathrooms'] > 1 else "bathroom"
park_str = "parking spaces" if row['Parking Spaces'] > 1 else "parking space"
prompt = (
f"A {row['Property Type'].lower()} located in {row['Suburb']}. "
f"It has {row['Bedrooms']} {bed_str}, {row['Bathrooms']} {bath_str}, "
f"and {row['Parking Spaces']} {park_str}. "
f"The total land size is {row['Land Size']} square meters. "
f"The property is described as: {row['Description']}. "
f"The final sale price of this property is:"
)
return promptThis generates prompts like:
A villa located in Clearwater. It has 4 bedrooms, 4 bathrooms, and 2 parking spaces. The total land size is 1244 square meters. The property is described as: Contemporary design throughout. The final sale price of this property is:
A apartment located in Seaside. It has 3 bedrooms, 2 bathrooms, and 0 parking space. The total land size is 0 square meters. The property is described as: Recently updated kitchen. The final sale price of this property is:
You will notice that the price value is missing from the column. It is by design because when we are asking the LLM to predict a price, we cannot include the answer in the input! We need to create a prompt that leads the LLM to fill in the blank.
Once this is created, I have saved this dataset in HuggingFace so that I don't have to re-run this process again.
Zero-shot Prediction with API-based models
Now, with my dataset prepared, I am going to test the capability of publicly available API-based models, such as GPT-4o. The idea is that I am not going to train or fine-tune these models; I will just give them this dataset and tell them to predict the price of the property. To be specific, I will be splitting the dataset into train / test (80-20 split) and tell the model to predict results based on test dataset without telling it what it actually is.
My coding buddy Gemini actually explained this concept better than I could:
The GPT-4o model is not looking at the 24,000 training rows at all. It is straight predicting on the test_df.
This method is called Zero-Shot Learning, and it's what makes large language models so powerful and different from traditional models.
Let's use an analogy to make this crystal clear:
Traditional Model (XGBoost): Imagine a student who knows nothing about real estate. You give them a textbook with 24,000 specific practice problems and their answers (train_df). They study only this book, learning the exact patterns within it. Then you give them a final exam with 6,000 new problems (test_df). Their entire performance is based on what they learned from your specific textbook.
Zero-Shot LLM (GPT-4o): Imagine a world-renowned real estate expert who has read every book, article, and website about real estate, economics, and construction ever written. You do not give them your textbook of 24,000 practice problems. You just walk up to them and give them the final exam with 6,000 problems. They use their vast, pre-existing general knowledge of the world to answer the questions, having never seen your specific training data.
Here's how GPT-4o performed:
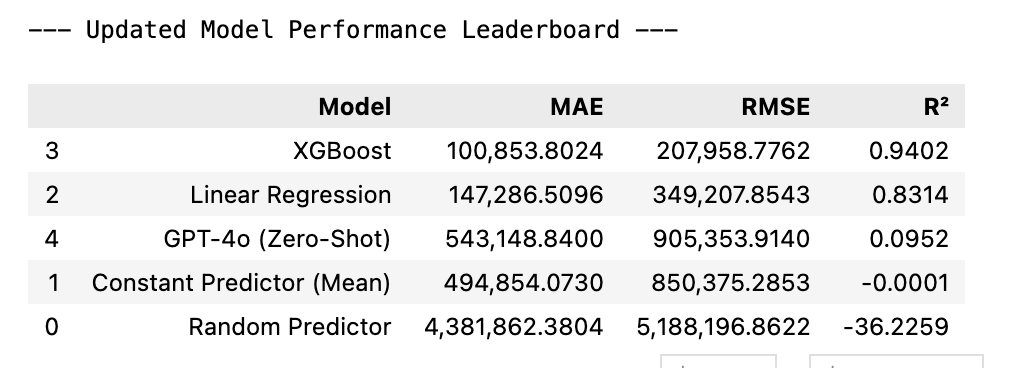
Yikes. It barely beat the random predictor and got demolished by Linear Regression. This makes sense, though. My dataset is entirely fictional, and GPT-4o has no real-world context to draw from. It is time for fine-tuning!
Finding an Open-Source Model to Fine-Tune
At this point, I would like to point out that I am running this whole project in Jupyter Notebook hosted locally on my Mac. It is still powerful but not exactly a data center. As such, I need to pick the open-sourced LLM that can still run on my machine and can be fine-tuned. Llama models were too memory-hungry, so I settled on Microsoft's Phi-3-mini-4k-instruct (3.8B parameters). Small enough to run locally, but still capable.
The Strategy: LoRA (Low-Rank Adaptation)
Before doing the fine-tuning process, I would like to point out that I am not fitting the entire 3.8B parameter model on my machine.
Instead of retraining the entire massive model, which would require a supercomputer, I used a clever technique called LoRA. Think of the original model as a giant, expert textbook. With LoRA, I 'freeze' the entire textbook and simply add small, efficient 'sticky notes' to it. I only train these tiny sticky notes on my property sales data. This makes the process incredibly efficient, allowing me to customize a huge AI model on a personal laptop.
The Model: microsoft/Phi-3-mini
The base model was Microsoft's Phi-3-mini, a powerful and compact open-source model. I chose it because it offers a fantastic balance of high performance and manageable size, making it a perfect candidate for fine-tuning on consumer hardware.
The Data & The Goal: Instruction Fine-Tuning
The goal was to turn this general-purpose AI into a specialist real estate price predictor. I did this through instruction fine-tuning. I converted each of my 24,000 training examples into a detailed, natural language prompt that described a property and ended with the instruction: "...The final sale price of this property is:". I then trained the model to learn how to accurately complete that sentence with the correct price.
After that, the fine-tuning starts! It took nearly 5 hours to complete the fine-tuning process, after which the model is saved to HuggingFace.

In the next post, I'll show you how the fine-tuned model performed against the traditional ML models and whether all this LLM hype is actually justified for regression tasks. Spoiler alert: the results might surprise you.
Final post is up here!