Building a Synthetic Data Generator with Gradio and LLMs

Recently, I built a Python notebook that makes generating synthetic datasets a breeze-no more wrangling with scripts or manual CSV editing. With a slick Gradio interface, you can describe the dataset you need, select your preferred large language model (LLM), preview the results, estimate costs, and download your data in CSV format. Here’s a walkthrough of how it works and why it’s a handy addition to any data science toolkit.
Why Synthetic Data?
Synthetic data is a lifesaver when you need to prototype machine learning models, test data pipelines, or share datasets without privacy concerns. But generating realistic, diverse data-especially tailored to your use case-can be tedious. That’s where LLMs like GPT-3.5, Claude, Gemini, or even local models like Mistral come in, and this notebook brings them all together under one roof.
Key Features
1. Model Selection Made Easy
You’re not locked into a single provider. The interface lets you choose between:
- OpenAI (GPT-3.5 Turbo)
- Anthropic (Claude 3 Haiku)
- Google (Gemini 2.0 Flash Lite)
- Local models (Mistral 7B via Ollama)
Just select your model from a dropdown, and the backend handles the rest.
2. Describe Your Dataset, Get Results Instantly
Type in a natural language description of the dataset you want-say, “A table of 100 fake e-commerce transactions with columns for date, customer name, product, price, and payment method.” The selected LLM takes your prompt and generates a CSV with realistic values and headers, ready for download.
3. Cost Estimation
Curious about how much your synthetic data will cost if you’re using paid APIs? The app estimates token usage and gives you a ballpark figure for each model, so you can make informed choices before you hit download.
4. Dataset Preview
No more blind downloads. The interface displays a preview of your generated dataset in a neat table, letting you spot-check for quality and completeness. If the LLM generates a different number of rows than requested, you’ll see a warning right in the preview.
5. Download in One Click
Once you’re happy with the preview, download the dataset as a CSV file-perfect for plugging into your next ML experiment or demo.
Below is a screenshot of how it actually looks like!
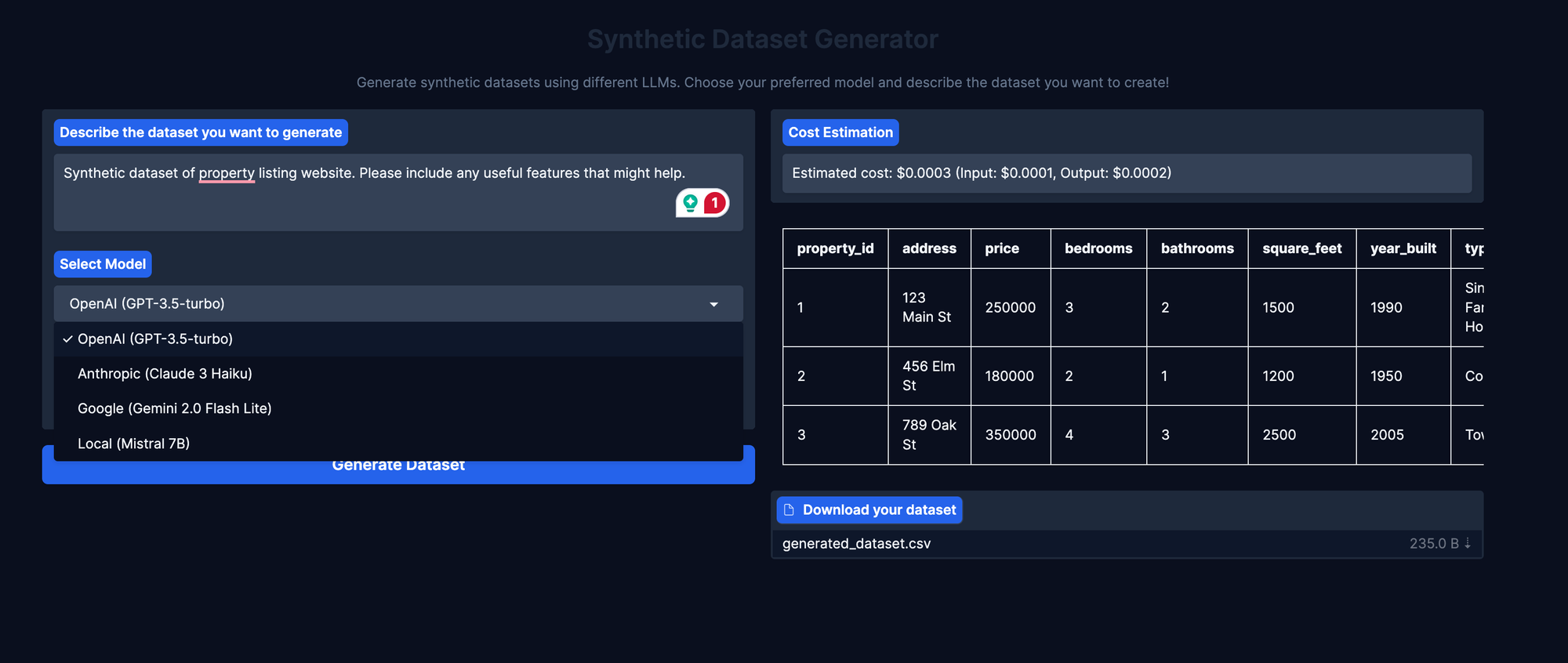
How It Works Under the Hood
- API Keys: The notebook loads API keys for OpenAI, Anthropic, and Google from environment variables, so your credentials stay secure.
- Prompting: It crafts a detailed prompt based on your description, asking the LLM to generate a CSV with headers and at least the number of rows you specify.
- Model Routing: Depending on your selection, it routes the prompt to the appropriate API (or local model) and captures the output.
- Cost Calculation: It estimates input/output token counts and computes the likely API cost.
- Data Handling: The generated CSV is parsed into a Pandas DataFrame for preview, and any errors or mismatches in row counts are flagged for transparency.
- Gradio UI: The whole workflow is wrapped in a Gradio Blocks interface, with soft theming for a clean, modern look.
What’s Next?
This project is a solid foundation for anyone who needs quick, customizable synthetic data. Future improvements could include:
- More granular control over data types and distributions
- Support for larger datasets
- Integration with more local models for privacy-first workflows
Try It Yourself
If you’re interested in generating your own synthetic datasets, check out the notebook and fire it up locally. All you need are your API keys and a few lines of setup. Describe your dream dataset, pick a model, and you’re off to the races.
If you want to see more AI and LLM-powered tools like this, check out my other projects here.
Let me know what features you’d like to see next, or if you run into any fun edge cases with your synthetic data prompts!